mirror of
https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI.git
synced 2026-06-05 09:10:25 +08:00
doc: remove changelogs
This commit is contained in:
@@ -1,117 +0,0 @@
|
||||
### 20231006更新
|
||||
|
||||
我们制作了一个用于实时变声的界面go-realtime-gui.bat/gui.py(事实上早就存在了),本次更新重点也优化了实时变声的性能。
|
||||
|
||||
对比0813版:
|
||||
|
||||
1. 优化界面操作
|
||||
- 参数热更新(调整参数不需要中止再启动)
|
||||
- 懒加载模型(已加载过的模型不需要重新加载)
|
||||
- 增加响度因子参数(响度向输入音频靠近)
|
||||
2. 优化自带降噪效果与速度
|
||||
3. 大幅优化推理速度
|
||||
|
||||
注意输入输出设备应该选择同种类型,例如都选MME类型。
|
||||
|
||||
1006版本整体的更新为:
|
||||
1. 继续提升rmvpe音高提取算法效果,对于男低音有更大的提升
|
||||
2. 优化推理界面布局
|
||||
|
||||
### 20230813更新
|
||||
1. 常规bug修复
|
||||
- 保存频率总轮数最低改为1 总轮数最低改为2
|
||||
- 修复无pretrain模型训练报错
|
||||
- 增加伴奏人声分离完毕清理显存
|
||||
- faiss保存路径绝对路径改为相对路径
|
||||
- 支持路径包含空格(训练集路径+实验名称均支持,不再会报错)
|
||||
- filelist取消强制utf8编码
|
||||
- 解决实时变声中开启索引导致的CPU极大占用问题
|
||||
|
||||
2. 重点更新
|
||||
- 训练出当前最强开源人声音高提取模型RMVPE,并用于RVC的训练、离线/实时推理,支持pytorch/onnx/DirectML
|
||||
- 通过pytorch-dml支持A卡和I卡的
|
||||
1. 实时变声
|
||||
2. 推理
|
||||
3. 人声伴奏分离
|
||||
4. 训练(暂未支持,会切换至CPU训练)
|
||||
5. 通过onnx_dml支持rmvpe_gpu的推理
|
||||
|
||||
### 20230618更新
|
||||
- v2增加32k和48k两个新预训练模型
|
||||
- 修复非f0模型推理报错
|
||||
- 对于超过一小时的训练集的索引建立环节,自动kmeans缩小特征处理以加速索引训练、加入和查询
|
||||
- 附送一个人声转吉他玩具仓库
|
||||
- 数据处理剔除异常值切片
|
||||
- onnx导出选项卡
|
||||
|
||||
失败的实验:
|
||||
- ~~特征检索增加时序维度:寄,没啥效果~~
|
||||
- ~~特征检索增加PCAR降维可选项:寄,数据大用kmeans缩小数据量,数据小降维操作耗时比省下的匹配耗时还多~~
|
||||
- ~~支持onnx推理(附带仅推理的小压缩包):寄,生成nsf还是需要pytorch~~
|
||||
- ~~训练时在音高、gender、eq、噪声等方面对输入进行随机增强:寄,没啥效果~~
|
||||
- ~~接入小型声码器调研:寄,效果变差~~
|
||||
|
||||
todolist:
|
||||
- ~~训练集音高识别支持crepe:已经被RMVPE取代,不需要~~
|
||||
- ~~多进程harvest推理:已经被RMVPE取代,不需要~~
|
||||
- ~~crepe的精度支持和RVC-config同步:已经被RMVPE取代,不需要。支持这个还要同步torchcrepe的库,麻烦~~
|
||||
- 对接F0编辑器
|
||||
|
||||
### 20230528更新
|
||||
- 增加v2的jupyter notebook,韩文changelog,增加一些环境依赖
|
||||
- 增加呼吸、清辅音、齿音保护模式
|
||||
- 支持crepe-full推理
|
||||
- UVR5人声伴奏分离加上3个去延迟模型和MDX-Net去混响模型,增加HP3人声提取模型
|
||||
- 索引名称增加版本和实验名称
|
||||
- 人声伴奏分离、推理批量导出增加音频导出格式选项
|
||||
- 废弃32k模型的训练
|
||||
|
||||
### 20230513更新
|
||||
- 清除一键包内部老版本runtime内残留的lib.infer_pack和uvr5_pack
|
||||
- 修复训练集预处理伪多进程的bug
|
||||
- 增加harvest识别音高可选通过中值滤波削弱哑音现象,可调整中值滤波半径
|
||||
- 导出音频增加后处理重采样
|
||||
- 训练n_cpu进程数从"仅调整f0提取"改为"调整数据预处理和f0提取"
|
||||
- 自动检测logs文件夹下的index路径,提供下拉列表功能
|
||||
- tab页增加"常见问题解答"(也可参考github-rvc-wiki)
|
||||
- 相同路径的输入音频推理增加了音高缓存(用途:使用harvest音高提取,整个pipeline会经历漫长且重复的音高提取过程,如果不使用缓存,实验不同音色、索引、音高中值滤波半径参数的用户在第一次测试后的等待结果会非常痛苦)
|
||||
|
||||
### 20230514更新
|
||||
- 音量包络对齐输入混合(可以缓解“输入静音输出小幅度噪声”的问题。如果输入音频背景底噪大则不建议开启,默认不开启(值为1可视为不开启))
|
||||
- 支持按照指定频率保存提取的小模型(假如你想尝试不同epoch下的推理效果,但是不想保存所有大checkpoint并且每次都要ckpt手工处理提取小模型,这项功能会非常实用)
|
||||
- 通过设置环境变量解决服务端开了系统全局代理导致浏览器连接错误的问题
|
||||
- 支持v2预训练模型(目前只公开了40k版本进行测试,另外2个采样率还没有训练完全)
|
||||
- 推理前限制超过1的过大音量
|
||||
- 微调数据预处理参数
|
||||
|
||||
|
||||
### 20230409更新
|
||||
- 修正训练参数,提升显卡平均利用率,A100最高从25%提升至90%左右,V100:50%->90%左右,2060S:60%->85%左右,P40:25%->95%左右,训练速度显著提升
|
||||
- 修正参数:总batch_size改为每张卡的batch_size
|
||||
- 修正total_epoch:最大限制100解锁至1000;默认10提升至默认20
|
||||
- 修复ckpt提取识别是否带音高错误导致推理异常的问题
|
||||
- 修复分布式训练每个rank都保存一次ckpt的问题
|
||||
- 特征提取进行nan特征过滤
|
||||
- 修复静音输入输出随机辅音or噪声的问题(老版模型需要重做训练集重训)
|
||||
|
||||
### 20230416更新
|
||||
- 新增本地实时变声迷你GUI,双击go-realtime-gui.bat启动
|
||||
- 训练推理均对<50Hz的频段进行滤波过滤
|
||||
- 训练推理音高提取pyworld最低音高从默认80下降至50,50-80hz间的男声低音不会哑
|
||||
- WebUI支持根据系统区域变更语言(现支持en_US,ja_JP,zh_CN,zh_HK,zh_SG,zh_TW,不支持的默认en_US)
|
||||
- 修正部分显卡识别(例如V100-16G识别失败,P4识别失败)
|
||||
|
||||
### 20230428更新
|
||||
- 升级faiss索引设置,速度更快,质量更高
|
||||
- 取消total_npy依赖,后续分享模型不再需要填写total_npy
|
||||
- 解锁16系限制。4G显存GPU给到4G的推理设置。
|
||||
- 修复部分音频格式下UVR5人声伴奏分离的bug
|
||||
- 实时变声迷你gui增加对非40k与不懈怠音高模型的支持
|
||||
|
||||
### 后续计划:
|
||||
功能:
|
||||
- 支持多人训练选项卡(至多4人)
|
||||
|
||||
底模:
|
||||
- 收集呼吸wav加入训练集修正呼吸变声电音的问题
|
||||
- 我们正在训练增加了歌声训练集的底模,未来会公开
|
||||
@@ -13,7 +13,7 @@
|
||||
|
||||
[](https://discord.gg/HcsmBBGyVk)
|
||||
|
||||
[**更新日志**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_CN.md) | [**常见问题解答**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·5毛钱训练AI歌手**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**对照实验记录**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95)) | [**在线演示**](https://modelscope.cn/studios/FlowerCry/RVCv2demo)
|
||||
[**常见问题解答**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·5毛钱训练AI歌手**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**对照实验记录**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95)) | [**在线演示**](https://modelscope.cn/studios/FlowerCry/RVCv2demo)
|
||||
|
||||
[**English**](../../README.md) | [**中文简体**](../cn/README.cn.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
|
||||
|
||||
@@ -25,11 +25,13 @@
|
||||
|
||||
> 由于某些地区无法直连Hugging Face,即使设法成功访问,速度也十分缓慢,特推出模型/整合包/工具的一键下载器,欢迎试用:[RVC-Models-Downloader](https://github.com/fumiama/RVC-Models-Downloader)
|
||||
|
||||
| 训练推理界面 | 实时变声界面 |
|
||||
| :--------: | :---------: |
|
||||
|  |  |
|
||||
| go-web.bat | go-realtime-gui.bat |
|
||||
| 可以自由选择想要执行的操作。 | 我们已经实现端到端170ms延迟。如使用ASIO输入输出设备,已能实现端到端90ms延迟,但非常依赖硬件驱动支持。|
|
||||
| 训练推理界面 |
|
||||
| :--------: |
|
||||
|  |
|
||||
|
||||
| 实时变声界面 |
|
||||
| :---------: |
|
||||
| 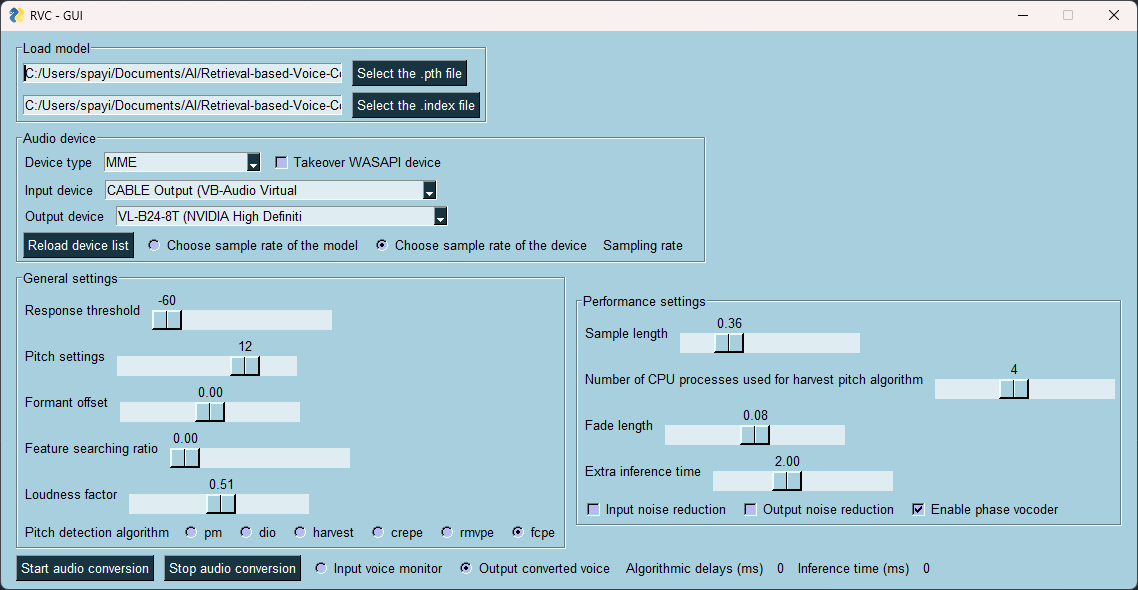 |
|
||||
|
||||
## 简介
|
||||
本仓库具有以下特点
|
||||
|
||||
@@ -1,105 +0,0 @@
|
||||
### 2023-10-06
|
||||
- We have created a GUI for real-time voice change: go-realtime-gui.bat/gui.py (Note that you should choose the same type of input and output device, e.g. MME and MME).
|
||||
- We trained a better pitch extract RMVPE model.
|
||||
- Optimize inference GUI layout.
|
||||
|
||||
### 2023-08-13
|
||||
1-Regular bug fix
|
||||
- Change the minimum total epoch number to 1, and change the minimum total epoch number to 2
|
||||
- Fix training errors of not using pre-train models
|
||||
- After accompaniment vocals separation, clear graphics memory
|
||||
- Change faiss save path absolute path to relative path
|
||||
- Support path containing spaces (both training set path and experiment name are supported, and errors will no longer be reported)
|
||||
- Filelist cancels mandatory utf8 encoding
|
||||
- Solve the CPU consumption problem caused by faiss searching during real-time voice changes
|
||||
|
||||
2-Key updates
|
||||
- Train the current strongest open-source vocal pitch extraction model RMVPE, and use it for RVC training, offline/real-time inference, supporting PyTorch/Onnx/DirectML
|
||||
- Support for AMD and Intel graphics cards through Pytorch_DML
|
||||
|
||||
(1) Real time voice change (2) Inference (3) Separation of vocal accompaniment (4) Training not currently supported, will switch to CPU training; supports RMVPE inference of gpu by Onnx_Dml
|
||||
|
||||
|
||||
### 2023-06-18
|
||||
- New pretrained v2 models: 32k and 48k
|
||||
- Fix non-f0 model inference errors
|
||||
- For training-set exceeding 1 hour, do automatic minibatch-kmeans to reduce feature shape, so that index training, adding, and searching will be much faster.
|
||||
- Provide a toy vocal2guitar huggingface space
|
||||
- Auto delete outlier short cut training-set audios
|
||||
- Onnx export tab
|
||||
|
||||
Failed experiments:
|
||||
- ~~Feature retrieval: add temporal feature retrieval: not effective~~
|
||||
- ~~Feature retrieval: add PCAR dimensionality reduction: searching is even slower~~
|
||||
- ~~Random data augmentation when training: not effective~~
|
||||
|
||||
todolist:
|
||||
- ~~Vocos-RVC (tiny vocoder): not effective~~
|
||||
- ~~Crepe support for training:replaced by RMVPE~~
|
||||
- ~~Half precision crepe inference:replaced by RMVPE. And hard to achive.~~
|
||||
- F0 editor support
|
||||
|
||||
### 2023-05-28
|
||||
- Add v2 jupyter notebook, korean changelog, fix some environment requirments
|
||||
- Add voiceless consonant and breath protection mode
|
||||
- Support crepe-full pitch detect
|
||||
- UVR5 vocal separation: support dereverb models and de-echo models
|
||||
- Add experiment name and version on the name of index
|
||||
- Support users to manually select export format of output audios when batch voice conversion processing and UVR5 vocal separation
|
||||
- v1 32k model training is no more supported
|
||||
|
||||
### 2023-05-13
|
||||
- Clear the redundant codes in the old version of runtime in the one-click-package: lib.infer_pack and uvr5_pack
|
||||
- Fix pseudo multiprocessing bug in training set preprocessing
|
||||
- Adding median filtering radius adjustment for harvest pitch recognize algorithm
|
||||
- Support post processing resampling for exporting audio
|
||||
- Multi processing "n_cpu" setting for training is changed from "f0 extraction" to "data preprocessing and f0 extraction"
|
||||
- Automatically detect the index paths under the logs folder and provide a drop-down list function
|
||||
- Add "Frequently Asked Questions and Answers" on the tab page (you can also refer to github RVC wiki)
|
||||
- When inference, harvest pitch is cached when using same input audio path (purpose: using harvest pitch extraction, the entire pipeline will go through a long and repetitive pitch extraction process. If caching is not used, users who experiment with different timbre, index, and pitch median filtering radius settings will experience a very painful waiting process after the first inference)
|
||||
|
||||
### 2023-05-14
|
||||
- Use volume envelope of input to mix or replace the volume envelope of output (can alleviate the problem of "input muting and output small amplitude noise". If the input audio background noise is high, it is not recommended to turn it on, and it is not turned on by default (1 can be considered as not turned on)
|
||||
- Support saving extracted small models at a specified frequency (if you want to see the performance under different epochs, but do not want to save all large checkpoints and manually extract small models by ckpt-processing every time, this feature will be very practical)
|
||||
- Resolve the issue of "connection errors" caused by the server's global proxy by setting environment variables
|
||||
- Supports pre-trained v2 models (currently only 40k versions are publicly available for testing, and the other two sampling rates have not been fully trained yet)
|
||||
- Limit excessive volume exceeding 1 before inference
|
||||
- Slightly adjusted the settings of training-set preprocessing
|
||||
|
||||
|
||||
#######################
|
||||
|
||||
History changelogs:
|
||||
|
||||
### 2023-04-09
|
||||
- Fixed training parameters to improve GPU utilization rate: A100 increased from 25% to around 90%, V100: 50% to around 90%, 2060S: 60% to around 85%, P40: 25% to around 95%; significantly improved training speed
|
||||
- Changed parameter: total batch_size is now per GPU batch_size
|
||||
- Changed total_epoch: maximum limit increased from 100 to 1000; default increased from 10 to 20
|
||||
- Fixed issue of ckpt extraction recognizing pitch incorrectly, causing abnormal inference
|
||||
- Fixed issue of distributed training saving ckpt for each rank
|
||||
- Applied nan feature filtering for feature extraction
|
||||
- Fixed issue with silent input/output producing random consonants or noise (old models need to retrain with a new dataset)
|
||||
|
||||
### 2023-04-16 Update
|
||||
- Added local real-time voice changing mini-GUI, start by double-clicking go-realtime-gui.bat
|
||||
- Applied filtering for frequency bands below 50Hz during training and inference
|
||||
- Lowered the minimum pitch extraction of pyworld from the default 80 to 50 for training and inference, allowing male low-pitched voices between 50-80Hz not to be muted
|
||||
- WebUI supports changing languages according to system locale (currently supporting en_US, ja_JP, zh_CN, zh_HK, zh_SG, zh_TW; defaults to en_US if not supported)
|
||||
- Fixed recognition of some GPUs (e.g., V100-16G recognition failure, P4 recognition failure)
|
||||
|
||||
### 2023-04-28 Update
|
||||
- Upgraded faiss index settings for faster speed and higher quality
|
||||
- Removed dependency on total_npy; future model sharing will not require total_npy input
|
||||
- Unlocked restrictions for the 16-series GPUs, providing 4GB inference settings for 4GB VRAM GPUs
|
||||
- Fixed bug in UVR5 vocal accompaniment separation for certain audio formats
|
||||
- Real-time voice changing mini-GUI now supports non-40k and non-lazy pitch models
|
||||
|
||||
### Future Plans:
|
||||
Features:
|
||||
- Add option: extract small models for each epoch save
|
||||
- Add option: export additional mp3 to the specified path during inference
|
||||
- Support multi-person training tab (up to 4 people)
|
||||
|
||||
Base model:
|
||||
- Collect breathing wav files to add to the training dataset to fix the issue of distorted breath sounds
|
||||
- We are currently training a base model with an extended singing dataset, which will be released in the future
|
||||
@@ -1,102 +0,0 @@
|
||||
### 2023-08-13
|
||||
1-Corrections régulières de bugs
|
||||
- Modification du nombre total d'époques minimum à 1 et changement du nombre total d'époques minimum à 2
|
||||
- Correction des erreurs d'entraînement sans utiliser de modèles pré-entraînés
|
||||
- Après la séparation des voix d'accompagnement, libération de la mémoire graphique
|
||||
- Changement du chemin absolu d'enregistrement de faiss en chemin relatif
|
||||
- Prise en charge des chemins contenant des espaces (le chemin du jeu de données d'entraînement et le nom de l'expérience sont pris en charge, et aucune erreur ne sera signalée)
|
||||
- La liste de fichiers annule l'encodage utf8 obligatoire
|
||||
- Résolution du problème de consommation de CPU causé par la recherche faiss lors des changements de voix en temps réel
|
||||
|
||||
2-Mises à jour clés
|
||||
- Entraînement du modèle d'extraction de hauteur vocale open-source le plus puissant actuel, RMVPE, et utilisation pour l'entraînement, l'inférence hors ligne/en temps réel de RVC, supportant PyTorch/Onnx/DirectML
|
||||
- Prise en charge des cartes graphiques AMD et Intel via Pytorch_DML
|
||||
|
||||
(1) Changement de voix en temps réel (2) Inférence (3) Séparation de l'accompagnement vocal (4) L'entraînement n'est pas actuellement pris en charge, passera à l'entraînement CPU; prend en charge l'inférence RMVPE de la GPU par Onnx_Dml
|
||||
|
||||
### 2023-06-18
|
||||
- Nouveaux modèles pré-entraînés v2 : 32k et 48k
|
||||
- Correction des erreurs d'inférence du modèle non-f0
|
||||
- Pour un jeu de données d'entraînement dépassant 1 heure, réalisation automatique de minibatch-kmeans pour réduire la forme des caractéristiques, afin que l'entraînement, l'ajout et la recherche d'index soient beaucoup plus rapides.
|
||||
- Fourniture d'un espace huggingface vocal2guitar jouet
|
||||
- Suppression automatique des audios de jeu de données d'entraînement court-circuitant les valeurs aberrantes
|
||||
- Onglet d'exportation Onnx
|
||||
|
||||
Expériences échouées:
|
||||
- ~~Récupération de caractéristiques : ajout de la récupération de caractéristiques temporelles : non efficace~~
|
||||
- ~~Récupération de caractéristiques : ajout de la réduction de dimensionnalité PCAR : la recherche est encore plus lente~~
|
||||
- ~~Augmentation aléatoire des données lors de l'entraînement : non efficace~~
|
||||
|
||||
Liste de tâches:
|
||||
- ~~Vocos-RVC (vocodeur minuscule) : non efficace~~
|
||||
- ~~Support de Crepe pour l'entraînement : remplacé par RMVPE~~
|
||||
- ~~Inférence de précision à moitié crepe : remplacée par RMVPE. Et difficile à réaliser.~~
|
||||
- Support de l'éditeur F0
|
||||
|
||||
### 2023-05-28
|
||||
- Ajout d'un cahier v2, changelog coréen, correction de certaines exigences environnementales
|
||||
- Ajout d'un mode de protection des consonnes muettes et de la respiration
|
||||
- Support de la détection de hauteur crepe-full
|
||||
- Séparation vocale UVR5 : support des modèles de déréverbération et de désécho
|
||||
- Ajout du nom de l'expérience et de la version sur le nom de l'index
|
||||
- Support pour les utilisateurs de sélectionner manuellement le format d'exportation des audios de sortie lors du traitement de conversion vocale en lots et de la séparation vocale UVR5
|
||||
- L'entraînement du modèle v1 32k n'est plus pris en charge
|
||||
|
||||
### 2023-05-13
|
||||
- Nettoyage des codes redondants de l'ancienne version du runtime dans le package en un clic : lib.infer_pack et uvr5_pack
|
||||
- Correction du bug de multiprocessus pseudo dans la préparation du jeu de données d'entraînement
|
||||
- Ajout de l'ajustement du rayon de filtrage médian pour l'algorithme de reconnaissance de hauteur de récolte
|
||||
- Prise en charge du rééchantillonnage post-traitement pour l'exportation audio
|
||||
- Réglage de multi-traitement "n_cpu" pour l'entraînement est passé de "extraction f0" à "prétraitement des données et extraction f0"
|
||||
- Détection automatique des chemins d'index sous le dossier de logs et fourniture d'une fonction de liste déroulante
|
||||
- Ajout de "Questions fréquemment posées et réponses" sur la page d'onglet (vous pouvez également consulter le wiki github RVC)
|
||||
- Lors de l'inférence, la hauteur de la récolte est mise en cache lors de l'utilisation du même chemin d'accès audio d'entrée (objectif : en utilisant l'extraction de
|
||||
|
||||
la hauteur de la récolte, l'ensemble du pipeline passera par un long processus d'extraction de la hauteur répétitif. Si la mise en cache n'est pas utilisée, les utilisateurs qui expérimentent différents timbres, index, et réglages de rayon de filtrage médian de hauteur connaîtront un processus d'attente très douloureux après la première inférence)
|
||||
|
||||
### 2023-05-14
|
||||
- Utilisation de l'enveloppe de volume de l'entrée pour mixer ou remplacer l'enveloppe de volume de la sortie (peut atténuer le problème du "muet en entrée et bruit de faible amplitude en sortie". Si le bruit de fond de l'audio d'entrée est élevé, il n'est pas recommandé de l'activer, et il n'est pas activé par défaut (1 peut être considéré comme n'étant pas activé)
|
||||
- Prise en charge de la sauvegarde des modèles extraits à une fréquence spécifiée (si vous voulez voir les performances sous différentes époques, mais que vous ne voulez pas sauvegarder tous les grands points de contrôle et extraire manuellement les petits modèles par ckpt-processing à chaque fois, cette fonctionnalité sera très pratique)
|
||||
- Résolution du problème des "erreurs de connexion" causées par le proxy global du serveur en définissant des variables d'environnement
|
||||
- Prise en charge des modèles pré-entraînés v2 (actuellement, seule la version 40k est disponible au public pour les tests, et les deux autres taux d'échantillonnage n'ont pas encore été entièrement entraînés)
|
||||
- Limite le volume excessif dépassant 1 avant l'inférence
|
||||
- Réglages légèrement ajustés de la préparation du jeu de données d'entraînement
|
||||
|
||||
#######################
|
||||
|
||||
Historique des changelogs:
|
||||
|
||||
### 2023-04-09
|
||||
- Correction des paramètres d'entraînement pour améliorer le taux d'utilisation du GPU : A100 est passé de 25% à environ 90%, V100 : de 50% à environ 90%, 2060S : de 60% à environ 85%, P40 : de 25% à environ 95% ; amélioration significative de la vitesse d'entraînement
|
||||
- Changement de paramètre : la taille de batch_size totale est maintenant la taille de batch_size par GPU
|
||||
- Changement de total_epoch : la limite maximale est passée de 100 à 1000 ; la valeur par défaut est passée de 10 à 20
|
||||
- Correction du problème d'extraction de ckpt reconnaissant la hauteur de manière incorrecte, causant une inférence anormale
|
||||
- Correction du problème d'entraînement distribué sauvegardant ckpt pour chaque rang
|
||||
- Application du filtrage des caractéristiques nan pour l'extraction des caractéristiques
|
||||
- Correction du problème d'entrée/sortie silencieuse produisant des consonnes aléatoires ou du bruit (les anciens modèles doivent être réentraînés avec un nouveau jeu de données)
|
||||
|
||||
### 2023-04-16 Mise à jour
|
||||
- Ajout d'une mini-interface graphique pour le changement de voix en temps réel, démarrage par double-clic sur go-realtime-gui.bat
|
||||
- Application d'un filtrage pour les bandes de fréquences inférieures à 50Hz pendant l'entraînement et l'inférence
|
||||
- Abaissement de l'extraction de hauteur minimale de pyworld du défaut 80 à 50 pour l'entraînement et l'inférence, permettant aux voix masculines graves entre 50-80Hz de ne pas être mises en sourdine
|
||||
- WebUI prend en charge le changement de langue en fonction des paramètres régionaux du système (prise en charge actuelle de en_US, ja_JP, zh_CN, zh_HK, zh_SG, zh_TW ; défaut à en_US si non pris en charge)
|
||||
- Correction de la reconnaissance de certains GPU (par exemple, échec de reconnaissance V100-16G, échec de reconnaissance P4)
|
||||
|
||||
### 2023-04-28 Mise à jour
|
||||
- Mise à niveau des paramètres d'index de faiss pour une vitesse plus rapide et une meilleure qualité
|
||||
- Suppression de la dépendance à total_npy ; le partage futur de modèles ne nécessitera pas d'entrée total
|
||||
|
||||
_npy
|
||||
- Levée des restrictions pour les GPU de la série 16, fournissant des paramètres d'inférence de 4 Go pour les GPU VRAM de 4 Go
|
||||
- Correction d'un bug dans la séparation vocale d'accompagnement UVR5 pour certains formats audio
|
||||
- La mini-interface de changement de voix en temps réel prend maintenant en charge les modèles de hauteur non-40k et non-lazy
|
||||
|
||||
### Plans futurs :
|
||||
Fonctionnalités :
|
||||
- Ajouter une option : extraire de petits modèles pour chaque sauvegarde d'époque
|
||||
- Ajouter une option : exporter un mp3 supplémentaire vers le chemin spécifié pendant l'inférence
|
||||
- Prise en charge de l'onglet d'entraînement multi-personnes (jusqu'à 4 personnes)
|
||||
|
||||
Modèle de base :
|
||||
- Collecter des fichiers wav de respiration pour les ajouter au jeu de données d'entraînement pour résoudre le problème des sons de respiration déformés
|
||||
- Nous entraînons actuellement un modèle de base avec un jeu de données de chant étendu, qui sera publié à l'avenir
|
||||
@@ -15,7 +15,7 @@ Un framework simple et facile à utiliser pour la conversion vocale (modificateu
|
||||
|
||||
[](https://discord.gg/HcsmBBGyVk)
|
||||
|
||||
[**Journal de mise à jour**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_CN.md) | [**FAQ**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·Formation d'un chanteur AI pour 5 centimes**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**Enregistrement des expériences comparatives**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95) | [**Démonstration en ligne**](https://huggingface.co/spaces/Ricecake123/RVC-demo)
|
||||
[**FAQ**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·Formation d'un chanteur AI pour 5 centimes**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**Enregistrement des expériences comparatives**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95) | [**Démonstration en ligne**](https://huggingface.co/spaces/Ricecake123/RVC-demo)
|
||||
|
||||
</div>
|
||||
|
||||
|
||||
@@ -1,123 +0,0 @@
|
||||
### 2023 年 10 月 6 日更新
|
||||
|
||||
リアルタイム声変換のためのインターフェース go-realtime-gui.bat/gui.py を作成しました(実際には既に存在していました)。今回のアップデートでは、リアルタイム声変換のパフォーマンスを重点的に最適化しました。0813 版との比較:
|
||||
|
||||
- 1. インターフェース操作の最適化:パラメータのホット更新(パラメータ調整時に中断して再起動する必要がない)、レイジーロードモデル(既にロードされたモデルは再ロードする必要がない)、音量因子パラメータ追加(音量を入力オーディオに近づける)
|
||||
- 2. 内蔵ノイズリダクション効果と速度の最適化
|
||||
- 3. 推論速度の大幅な最適化
|
||||
|
||||
入出力デバイスは同じタイプを選択する必要があります。例えば、両方とも MME タイプを選択します。
|
||||
|
||||
1006 バージョンの全体的な更新は:
|
||||
|
||||
- 1. rmvpe 音声ピッチ抽出アルゴリズムの効果をさらに向上、特に男性の低音部分で大きな改善
|
||||
- 2. 推論インターフェースレイアウトの最適化
|
||||
|
||||
### 2023 年 8 月 13 日更新
|
||||
|
||||
1-通常のバグ修正
|
||||
|
||||
- 保存頻度と総ラウンド数の最小値を 1 に変更。総ラウンド数の最小値を 2 に変更
|
||||
- pretrain モデルなしでのトレーニングエラーを修正
|
||||
- 伴奏とボーカルの分離完了後の VRAM クリア
|
||||
- faiss 保存パスを絶対パスから相対パスに変更
|
||||
- パスに空白が含まれる場合のサポート(トレーニングセットのパス+実験名がサポートされ、エラーにならない)
|
||||
- filelist の強制的な utf8 エンコーディングをキャンセル
|
||||
- リアルタイム声変換中にインデックスを有効にすることによる CPU の大幅な使用問題を解決
|
||||
|
||||
2-重要なアップデート
|
||||
|
||||
- 現在最も強力なオープンソースの人間の声のピッチ抽出モデル RMVPE をトレーニングし、RVC のトレーニング、オフライン/リアルタイム推論に使用。pytorch/onnx/DirectML をサポート
|
||||
- pytorch-dml を通じて A カードと I カードのサポート
|
||||
(1)リアルタイム声変換(2)推論(3)ボーカルと伴奏の分離(4)トレーニングはまだサポートされておらず、CPU でのトレーニングに切り替わります。onnx_dml を通じて rmvpe_gpu の推論をサポート
|
||||
|
||||
### 2023 年 6 月 18 日更新
|
||||
|
||||
- v2 に 32k と 48k の 2 つの新しい事前トレーニングモデルを追加
|
||||
- 非 f0 モデルの推論エラーを修正
|
||||
- 1 時間を超えるトレーニングセットのインデックス構築フェーズでは、自動的に kmeans で特徴を縮小し、インデックスのトレーニングを加速し、検索に追加
|
||||
- 人間の声をギターに変換するおもちゃのリポジトリを添付
|
||||
- データ処理で異常値スライスを除外
|
||||
- onnx エクスポートオプションタブ
|
||||
|
||||
失敗した実験:
|
||||
|
||||
- ~~特徴検索に時間次元を追加:ダメ、効果がない~~
|
||||
- ~~特徴検索に PCAR 次元削減オプションを追加:ダメ、大きなデータは kmeans でデータ量を減らし、小さいデータは次元削減の時間が節約するマッチングの時間よりも長い~~
|
||||
- ~~onnx 推論のサポート(推論のみの小さな圧縮パッケージ付き):ダメ、nsf の生成には pytorch が必要~~
|
||||
- ~~トレーニング中に音声、ジェンダー、eq、ノイズなどで入力をランダムに増強:ダメ、効果がない~~
|
||||
- ~~小型声码器の接続調査:ダメ、効果が悪化~~
|
||||
|
||||
todolist:
|
||||
|
||||
- ~~トレーニングセットの音声ピッチ認識に crepe をサポート:既に RMVPE に置き換えられているため不要~~
|
||||
- ~~多プロセス harvest 推論:既に RMVPE に置き換えられているため不要~~
|
||||
- ~~crepe の精度サポートと RVC-config の同期:既に RMVPE に置き換えられているため不要。これをサポートするには torchcrepe ライブラリも同期する必要があり、面倒~~
|
||||
- F0 エディタとの連携
|
||||
|
||||
### 2023 年 5 月 28 日更新
|
||||
|
||||
- v2 の jupyter notebook を追加、韓国語の changelog を追加、いくつかの環境依存関係を追加
|
||||
- 呼吸、清辅音、歯音の保護モードを追加
|
||||
- crepe-full 推論をサポート
|
||||
- UVR5 人間の声と伴奏の分離に 3 つの遅延除去モデルと MDX-Net の混响除去モデルを追加、HP3 人声抽出モデルを追加
|
||||
- インデックス名にバージョンと実験名を追加
|
||||
- 人間の声と伴奏の分離、推論のバッチエクスポートにオーディオエクスポートフォーマットオプションを追加
|
||||
- 32k モデルのトレーニングを廃止
|
||||
|
||||
### 2023 年 5 月 13 日更新
|
||||
|
||||
- ワンクリックパッケージ内の古いバージョンの runtime 内の lib.infer_pack と uvr5_pack の残骸をクリア
|
||||
- トレーニングセットの事前処理の擬似マルチプロセスバグを修正
|
||||
- harvest による音声ピッチ認識で無声音現象を弱めるために中間値フィルターを追加、中間値フィルターの半径を調整可能
|
||||
- 音声エクスポートにポストプロセスリサンプリングを追加
|
||||
- トレーニング時の n_cpu プロセス数を「F0 抽出のみ調整」から「データ事前処理と F0 抽出の調整」に変更
|
||||
- logs フォルダ下の index パスを自動検出し、ドロップダウンリスト機能を提供
|
||||
- タブページに「よくある質問」を追加(または github-rvc-wiki を参照)
|
||||
- 同じパスの入力音声推論に音声ピッチキャッシュを追加(用途:harvest 音声ピッチ抽出を使用すると、全体のパイプラインが長く繰り返される音声ピッチ抽出プロセスを経験し、キャッシュを使用しない場合、異なる音色、インデックス、音声ピッチ中間値フィルター半径パラメーターをテストするユーザーは、最初のテスト後の待機結果が非常に苦痛になります)
|
||||
|
||||
### 2023 年 5 月 14 日更新
|
||||
|
||||
- 音量エンベロープのアライメント入力ミックス(「入力が無音で出力がわずかなノイズ」の問題を緩和することができます。入力音声の背景ノイズが大きい場合は、オンにしないことをお勧めします。デフォルトではオフ(1 として扱われる))
|
||||
- 指定された頻度で抽出された小型モデルを保存する機能をサポート(異なるエポックでの推論効果を試したいが、すべての大きなチェックポイントを保存して手動で小型モデルを抽出するのが面倒な場合、この機能は非常に便利です)
|
||||
- システム全体のプロキシが開かれている場合にブラウザの接続エラーが発生する問題を環境変数の設定で解決
|
||||
- v2 事前訓練モデルをサポート(現在、テストのために 40k バージョンのみが公開されており、他の 2 つのサンプリングレートはまだ完全に訓練されていません)
|
||||
- 推論前に 1 を超える過大な音量を制限
|
||||
- データ事前処理パラメーターを微調整
|
||||
|
||||
### 2023 年 4 月 9 日更新
|
||||
|
||||
- トレーニングパラメーターを修正し、GPU の平均利用率を向上させる。A100 は最高 25%から約 90%に、V100 は 50%から約 90%に、2060S は 60%から約 85%に、P40 は 25%から約 95%に向上し、トレーニング速度が大幅に向上
|
||||
- パラメーターを修正:全体の batch_size を各カードの batch_size に変更
|
||||
- total_epoch を修正:最大制限 100 から 1000 に解除; デフォルト 10 からデフォルト 20 に引き上げ
|
||||
- ckpt 抽出時に音声ピッチの有無を誤って認識し、推論が異常になる問題を修正
|
||||
- 分散トレーニングで各ランクが ckpt を 1 回ずつ保存する問題を修正
|
||||
- 特徴抽出で nan 特徴をフィルタリング
|
||||
- 入力が無音で出力がランダムな子音またはノイズになる問題を修正(旧バージョンのモデルはトレーニングセットを作り直して再トレーニングする必要があります)
|
||||
|
||||
### 2023 年 4 月 16 日更新
|
||||
|
||||
- ローカルリアルタイム音声変換ミニ GUI を新設、go-realtime-gui.bat をダブルクリックで起動
|
||||
- トレーニングと推論で 50Hz 以下の周波数帯をフィルタリング
|
||||
- トレーニングと推論の音声ピッチ抽出 pyworld の最低音声ピッチをデフォルトの 80 から 50 に下げ、50-80hz の男性低音声が無声にならないように
|
||||
- WebUI がシステムの地域に基づいて言語を変更する機能をサポート(現在サポートされているのは en_US、ja_JP、zh_CN、zh_HK、zh_SG、zh_TW、サポートされていない場合はデフォルトで en_US になります)
|
||||
- 一部のグラフィックカードの認識を修正(例えば V100-16G の認識失敗、P4 の認識失敗)
|
||||
|
||||
### 2023 年 4 月 28 日更新
|
||||
|
||||
- faiss インデックス設定をアップグレードし、速度が速く、品質が高くなりました
|
||||
- total_npy 依存をキャンセルし、今後のモデル共有では total_npy の記入は不要
|
||||
- 16 シリーズの制限を解除。4G メモリ GPU に 4G の推論設定を提供
|
||||
- 一部のオーディオ形式で UVR5 の人声伴奏分離のバグを修正
|
||||
- リアルタイム音声変換ミニ gui に 40k 以外のモデルと妥協のない音声ピッチモデルのサポートを追加
|
||||
|
||||
### 今後の計画:
|
||||
|
||||
機能:
|
||||
|
||||
- 複数人のトレーニングタブのサポート(最大 4 人)
|
||||
|
||||
底層モデル:
|
||||
|
||||
- 呼吸 wav をトレーニングセットに追加し、呼吸が音声変換の電子音の問題を修正
|
||||
- 歌声トレーニングセットを追加した底層モデルをトレーニングしており、将来的には公開する予定です
|
||||
@@ -14,7 +14,7 @@ VITSに基づく使いやすい音声変換(voice changer)framework
|
||||
|
||||
[](https://discord.gg/HcsmBBGyVk)
|
||||
|
||||
[**更新日誌**](./Changelog_JA.md) | [**よくある質問**](./faq_ja.md) | [**AutoDLで推論(中国語のみ)**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**対照実験記録**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95) | [**オンラインデモ(中国語のみ)**](https://modelscope.cn/studios/FlowerCry/RVCv2demo)
|
||||
[**よくある質問**](./faq_ja.md) | [**AutoDLで推論(中国語のみ)**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**対照実験記録**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95) | [**オンラインデモ(中国語のみ)**](https://modelscope.cn/studios/FlowerCry/RVCv2demo)
|
||||
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
|
||||
|
||||
@@ -26,11 +26,13 @@ VITSに基づく使いやすい音声変換(voice changer)framework
|
||||
|
||||
> モデルや統合パッケージをダウンロードしやすい[RVC-Models-Downloader](https://github.com/fumiama/RVC-Models-Downloader)のご利用がお勧めです。
|
||||
|
||||
| 学習・推論 | 即時音声変換 |
|
||||
| :--------: | :---------: |
|
||||
|  |  |
|
||||
| go-web.bat | go-realtime-gui.bat |
|
||||
| 実行したい操作を自由に選択できます。 | 既に端から端までの170msの遅延を実現しました。ASIO入出力デバイスを使用すれば、端から端までの90msの遅延を達成できますが、ハードウェアドライバーの支援に非常に依存しています。 |
|
||||
| 学習・推論 |
|
||||
| :--------: |
|
||||
|  |
|
||||
|
||||
| 即時音声変換 |
|
||||
| :---------: |
|
||||
|  |
|
||||
|
||||
## はじめに
|
||||
|
||||
|
||||
@@ -1,124 +0,0 @@
|
||||
### 2023년 10월 6일 업데이트
|
||||
|
||||
실시간 음성 변환을 위한 인터페이스인 go-realtime-gui.bat/gui.py를 제작했습니다(사실 이는 이미 존재했었습니다). 이번 업데이트는 주로 실시간 음성 변환 성능을 최적화하는 데 중점을 두었습니다. 0813 버전과 비교하여:
|
||||
|
||||
- 1. 인터페이스 조작 최적화: 매개변수 핫 업데이트(매개변수 조정 시 중단 후 재시작 필요 없음), 모델 지연 로딩(이미 로드된 모델은 재로드 필요 없음), 음량 인자 매개변수 추가(음량을 입력 오디오에 가깝게 조정)
|
||||
- 2. 내장된 노이즈 감소 효과 및 속도 최적화
|
||||
- 3. 추론 속도 크게 향상
|
||||
|
||||
입력 및 출력 장치는 동일한 유형을 선택해야 합니다. 예를 들어, 모두 MME 유형을 선택해야 합니다.
|
||||
|
||||
1006 버전의 전체 업데이트는 다음과 같습니다:
|
||||
|
||||
- 1. rmvpe 음성 피치 추출 알고리즘의 효과를 계속해서 향상, 특히 남성 저음역에 대한 개선이 큼
|
||||
- 2. 추론 인터페이스 레이아웃 최적화
|
||||
|
||||
### 2023년 08월 13일 업데이트
|
||||
|
||||
1-정기적인 버그 수정
|
||||
|
||||
- 최소 총 에포크 수를 1로 변경하고, 최소 총 에포크 수를 2로 변경합니다.
|
||||
- 사전 훈련(pre-train) 모델을 사용하지 않는 훈련 오류 수정
|
||||
- 반주 보컬 분리 후 그래픽 메모리 지우기
|
||||
- 페이즈 저장 경로 절대 경로를 상대 경로로 변경
|
||||
- 공백이 포함된 경로 지원(훈련 세트 경로와 실험 이름 모두 지원되며 더 이상 오류가 보고되지 않음)
|
||||
- 파일 목록에서 필수 utf8 인코딩 취소
|
||||
- 실시간 음성 변경 중 faiss 검색으로 인한 CPU 소모 문제 해결
|
||||
|
||||
2-키 업데이트
|
||||
|
||||
- 현재 가장 강력한 오픈 소스 보컬 피치 추출 모델 RMVPE를 훈련하고, 이를 RVC 훈련, 오프라인/실시간 추론에 사용하며, PyTorch/Onx/DirectML을 지원합니다.
|
||||
- 파이토치\_DML을 통한 AMD 및 인텔 그래픽 카드 지원
|
||||
(1) 실시간 음성 변화 (2) 추론 (3) 보컬 반주 분리 (4) 현재 지원되지 않는 훈련은 CPU 훈련으로 전환, Onnx_Dml을 통한 gpu의 RMVPE 추론 지원
|
||||
|
||||
### 2023년 6월 18일 업데이트
|
||||
|
||||
- v2 버전에서 새로운 32k와 48k 사전 학습 모델을 추가.
|
||||
- non-f0 모델들의 추론 오류 수정.
|
||||
- 학습 세트가 1시간을 넘어가는 경우, 인덱스 생성 단계에서 minibatch-kmeans을 사용해, 학습속도 가속화.
|
||||
- [huggingface](https://huggingface.co/spaces/lj1995/vocal2guitar)에서 vocal2guitar 제공.
|
||||
- 데이터 처리 단계에서 이상 값 자동으로 제거.
|
||||
- ONNX로 내보내는(export) 옵션 탭 추가.
|
||||
|
||||
업데이트에 적용되지 않았지만 시도한 것들 :
|
||||
|
||||
- ~~시계열 차원을 추가하여 특징 검색을 진행했지만, 유의미한 효과는 없었습니다.~~
|
||||
- ~~PCA 차원 축소를 추가하여 특징 검색을 진행했지만, 유의미한 효과는 없었습니다.~~
|
||||
- ~~ONNX 추론을 지원하는 것에 실패했습니다. nsf 생성시, Pytorch가 필요하기 때문입니다.~~
|
||||
- ~~훈련 중에 입력에 대한 음고, 성별, 이퀄라이저, 노이즈 등 무작위로 강화하는 것에, 유의미한 효과는 없었습니다.~~
|
||||
|
||||
추후 업데이트 목록:
|
||||
|
||||
- ~~Vocos-RVC (소형 보코더) 통합 예정.~~
|
||||
- ~~학습 단계에 음고 인식을 위한 Crepe 지원 예정.~~
|
||||
- ~~Crepe의 정밀도를 REC-config와 동기화하여 지원 예정.~~
|
||||
- FO 에디터 지원 예정.
|
||||
|
||||
### 2023년 5월 28일 업데이트
|
||||
|
||||
- v2 jupyter notebook 추가, 한국어 업데이트 로그 추가, 의존성 모듈 일부 수정.
|
||||
- 무성음 및 숨소리 보호 모드 추가.
|
||||
- crepe-full pitch 감지 지원.
|
||||
- UVR5 보컬 분리: 디버브 및 디-에코 모델 지원.
|
||||
- index 이름에 experiment 이름과 버전 추가.
|
||||
- 배치 음성 변환 처리 및 UVR5 보컬 분리 시, 사용자가 수동으로 출력 오디오의 내보내기(export) 형식을 선택할 수 있도록 지원.
|
||||
- 32k 훈련 모델 지원 종료.
|
||||
|
||||
### 2023년 5월 13일 업데이트
|
||||
|
||||
- 원클릭 패키지의 이전 버전 런타임 내, 불필요한 코드(lib.infer_pack 및 uvr5_pack) 제거.
|
||||
- 훈련 세트 전처리의 유사 다중 처리 버그 수정.
|
||||
- Harvest 피치 인식 알고리즘에 대한 중위수 필터링 반경 조정 추가.
|
||||
- 오디오 내보낼 때, 후처리 리샘플링 지원.
|
||||
- 훈련에 대한 다중 처리 "n_cpu" 설정이 "f0 추출"에서 "데이터 전처리 및 f0 추출"로 변경.
|
||||
- logs 폴더 하의 인덱스 경로를 자동으로 감지 및 드롭다운 목록 기능 제공.
|
||||
- 탭 페이지에 "자주 묻는 질문과 답변" 추가. (github RVC wiki 참조 가능)
|
||||
- 동일한 입력 오디오 경로를 사용할 때 추론, Harvest 피치를 캐시.
|
||||
(주의: Harvest 피치 추출을 사용하면 전체 파이프라인은 길고 반복적인 피치 추출 과정을 거치게됩니다. 캐싱을 하지 않는다면, 첫 inference 이후의 단계에서 timbre, 인덱스, 피치 중위수 필터링 반경 설정 등 대기시간이 엄청나게 길어집니다!)
|
||||
|
||||
### 2023년 5월 14일 업데이트
|
||||
|
||||
- 입력의 볼륨 캡슐을 사용하여 출력의 볼륨 캡슐을 혼합하거나 대체. (입력이 무음이거나 출력의 노이즈 문제를 최소화 할 수 있습니다. 입력 오디오의 배경 노이즈(소음)가 큰 경우 해당 기능을 사용하지 않는 것이 좋습니다. 기본적으로 비활성화 되어있는 옵션입니다. (1: 비활성화 상태))
|
||||
- 추출된 소형 모델을 지정된 빈도로 저장하는 기능을 지원. (다양한 에폭 하에서의 성능을 보려고 하지만 모든 대형 체크포인트를 저장하고 매번 ckpt 처리를 통해 소형 모델을 수동으로 추출하고 싶지 않은 경우 이 기능은 매우 유용합니다)
|
||||
- 환경 변수를 설정하여 서버의 전역 프록시로 인한 "연결 오류" 문제 해결.
|
||||
- 사전 훈련된 v2 모델 지원. (현재 40k 버전만 테스트를 위해 공개적으로 사용 가능하며, 다른 두 개의 샘플링 비율은 아직 완전히 훈련되지 않아 보류되었습니다.)
|
||||
- 추론 전, 1을 초과하는 과도한 볼륨 제한.
|
||||
- 데이터 전처리 매개변수 미세 조정.
|
||||
|
||||
### 2023년 4월 9일 업데이트
|
||||
|
||||
- GPU 이용률 향상을 위해 훈련 파라미터 수정: A100은 25%에서 약 90%로 증가, V100: 50%에서 약 90%로 증가, 2060S: 60%에서 약 85%로 증가, P40: 25%에서 약 95%로 증가.
|
||||
훈련 속도가 크게 향상.
|
||||
- 매개변수 기준 변경: total batch_size는 GPU당 batch_size를 의미.
|
||||
- total_epoch 변경: 최대 한도가 100에서 1000으로 증가. 기본값이 10에서 20으로 증가.
|
||||
- ckpt 추출이 피치를 잘못 인식하여 비정상적인 추론을 유발하는 문제 수정.
|
||||
- 분산 훈련 과정에서 각 랭크마다 ckpt를 저장하는 문제 수정.
|
||||
- 특성 추출 과정에 나노 특성 필터링 적용.
|
||||
- 무음 입력/출력이 랜덤하게 소음을 생성하는 문제 수정. (이전 모델은 새 데이터셋으로 다시 훈련해야 합니다)
|
||||
|
||||
### 2023년 4월 16일 업데이트
|
||||
|
||||
- 로컬 실시간 음성 변경 미니-GUI 추가, go-realtime-gui.bat를 더블 클릭하여 시작.
|
||||
- 훈련 및 추론 중 50Hz 이하의 주파수 대역에 대해 필터링 적용.
|
||||
- 훈련 및 추론의 pyworld 최소 피치 추출을 기본 80에서 50으로 낮춤. 이로 인해, 50-80Hz 사이의 남성 저음이 무음화되지 않습니다.
|
||||
- 시스템 지역에 따른 WebUI 언어 변경 지원. (현재 en_US, ja_JP, zh_CN, zh_HK, zh_SG, zh_TW를 지원하며, 지원되지 않는 경우 기본값은 en_US)
|
||||
- 일부 GPU의 인식 수정. (예: V100-16G 인식 실패, P4 인식 실패)
|
||||
|
||||
### 2023년 4월 28일 업데이트
|
||||
|
||||
- Faiss 인덱스 설정 업그레이드로 속도가 더 빨라지고 품질이 향상.
|
||||
- total_npy에 대한 의존성 제거. 추후의 모델 공유는 total_npy 입력을 필요로 하지 않습니다.
|
||||
- 16 시리즈 GPU에 대한 제한 해제, 4GB VRAM GPU에 대한 4GB 추론 설정 제공.
|
||||
- 일부 오디오 형식에 대한 UVR5 보컬 동반 분리에서의 버그 수정.
|
||||
- 실시간 음성 변경 미니-GUI는 이제 non-40k 및 non-lazy 피치 모델을 지원합니다.
|
||||
|
||||
### 추후 계획
|
||||
|
||||
Features:
|
||||
|
||||
- 다중 사용자 훈련 탭 지원.(최대 4명)
|
||||
|
||||
Base model:
|
||||
|
||||
- 훈련 데이터셋에 숨소리 wav 파일을 추가하여, 보컬의 호흡이 노이즈로 변환되는 문제 수정.
|
||||
- 보컬 훈련 세트의 기본 모델을 추가하기 위한 작업을 진행중이며, 이는 향후에 발표될 예정.
|
||||
@@ -18,7 +18,6 @@ VITS基盤의 簡單하고使用하기 쉬운音聲變換틀
|
||||
</div>
|
||||
|
||||
------
|
||||
[**更新日誌**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_KO.md)
|
||||
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
|
||||
|
||||
|
||||
@@ -12,7 +12,7 @@ VITS 기반의 간단하고 사용하기 쉬운 음성 변환 프레임워크.
|
||||
|
||||
[](https://discord.gg/HcsmBBGyVk)
|
||||
|
||||
[**업데이트 로그**](./Changelog_KO.md) | [**자주 묻는 질문**](./faq_ko.md) | [**AutoDL·5원으로 AI 가수 훈련**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**대조 실험 기록**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95) | [**온라인 데모**](https://modelscope.cn/studios/FlowerCry/RVCv2demo)
|
||||
[**자주 묻는 질문**](./faq_ko.md) | [**AutoDL·5원으로 AI 가수 훈련**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**대조 실험 기록**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95) | [**온라인 데모**](https://modelscope.cn/studios/FlowerCry/RVCv2demo)
|
||||
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
|
||||
|
||||
@@ -24,11 +24,13 @@ VITS 기반의 간단하고 사용하기 쉬운 음성 변환 프레임워크.
|
||||
|
||||
> 특정 지역에서 Hugging Face에 직접 연결할 수 없는 경우가 있으며, 성공적으로 연결해도 속도가 매우 느릴 수 있으므로, 모델/통합 패키지/도구의 일괄 다운로더를 특별히 소개합니다. [RVC-Models-Downloader](https://github.com/fumiama/RVC-Models-Downloader)
|
||||
|
||||
| 훈련 및 추론 인터페이스 | 실시간 음성 변환 인터페이스 |
|
||||
| :--------: | :---------: |
|
||||
|  |  |
|
||||
| go-web.bat | go-realtime-gui.bat |
|
||||
| 원하는 작업을 자유롭게 선택할 수 있습니다. | 우리는 이미 끝에서 끝까지 170ms의 지연을 실현했습니다. ASIO 입력 및 출력 장치를 사용하면 끝에서 끝까지 90ms의 지연을 달성할 수 있지만, 이는 하드웨어 드라이버 지원에 매우 의존적입니다. |
|
||||
| 훈련 및 추론 인터페이스 |
|
||||
| :--------: |
|
||||
|  |
|
||||
|
||||
| 실시간 음성 변환 인터페이스 |
|
||||
| :---------: |
|
||||
|  |
|
||||
|
||||
## 소개
|
||||
|
||||
|
||||
@@ -1,105 +0,0 @@
|
||||
### 2023-10-06
|
||||
- Criamos uma GUI para alteração de voz em tempo real: go-realtime-gui.bat/gui.py (observe que você deve escolher o mesmo tipo de dispositivo de entrada e saída, por exemplo, MME e MME).
|
||||
- Treinamos um modelo RMVPE de extração de pitch melhor.
|
||||
- Otimizar o layout da GUI de inferência.
|
||||
|
||||
### 2023-08-13
|
||||
1-Correção de bug regular
|
||||
- Alterar o número total mínimo de épocas para 1 e alterar o número total mínimo de epoch para 2
|
||||
- Correção de erros de treinamento por não usar modelos de pré-treinamento
|
||||
- Após a separação dos vocais de acompanhamento, limpe a memória dos gráficos
|
||||
- Alterar o caminho absoluto do faiss save para o caminho relativo
|
||||
- Suporte a caminhos com espaços (tanto o caminho do conjunto de treinamento quanto o nome do experimento são suportados, e os erros não serão mais relatados)
|
||||
- A lista de arquivos cancela a codificação utf8 obrigatória
|
||||
- Resolver o problema de consumo de CPU causado pela busca do faiss durante alterações de voz em tempo real
|
||||
|
||||
Atualizações do 2-Key
|
||||
- Treine o modelo de extração de pitch vocal de código aberto mais forte do momento, o RMVPE, e use-o para treinamento de RVC, inferência off-line/em tempo real, com suporte a PyTorch/Onnx/DirectML
|
||||
- Suporte para placas gráficas AMD e Intel por meio do Pytorch_DML
|
||||
|
||||
(1) Mudança de voz em tempo real (2) Inferência (3) Separação do acompanhamento vocal (4) Não há suporte para treinamento no momento, mudaremos para treinamento de CPU; há suporte para inferência RMVPE de gpu por Onnx_Dml
|
||||
|
||||
|
||||
### 2023-06-18
|
||||
- Novos modelos v2 pré-treinados: 32k e 48k
|
||||
- Correção de erros de inferência de modelo não-f0
|
||||
- Para conjuntos de treinamento que excedam 1 hora, faça minibatch-kmeans automáticos para reduzir a forma dos recursos, de modo que o treinamento, a adição e a pesquisa do Index sejam muito mais rápidos.
|
||||
- Fornecer um espaço de brinquedo vocal2guitar huggingface
|
||||
- Exclusão automática de áudios de conjunto de treinamento de atalhos discrepantes
|
||||
- Guia de exportação Onnx
|
||||
|
||||
Experimentos com falha:
|
||||
- ~~Recuperação de recurso: adicionar recuperação de recurso temporal: não eficaz~~
|
||||
- ~~Recuperação de recursos: adicionar redução de dimensionalidade PCAR: a busca é ainda mais lenta~~
|
||||
- ~~Aumento de dados aleatórios durante o treinamento: não é eficaz~~
|
||||
|
||||
Lista de tarefas:
|
||||
- ~~Vocos-RVC (vocoder minúsculo): não é eficaz~~
|
||||
- ~~Suporte de crepe para treinamento: substituído pelo RMVPE~~
|
||||
- ~~Inferência de crepe de meia precisão:substituída pelo RMVPE. E difícil de conseguir.~~
|
||||
- Suporte ao editor de F0
|
||||
|
||||
### 2023-05-28
|
||||
- Adicionar notebook jupyter v2, changelog em coreano, corrigir alguns requisitos de ambiente
|
||||
- Adicionar consoante sem voz e modo de proteção de respiração
|
||||
- Suporte à detecção de pitch crepe-full
|
||||
- Separação vocal UVR5: suporte a modelos dereverb e modelos de-echo
|
||||
- Adicionar nome e versão do experimento no nome do Index
|
||||
- Suporte aos usuários para selecionar manualmente o formato de exportação dos áudios de saída durante o processamento de conversão de voz em lote e a separação vocal UVR5
|
||||
- Não há mais suporte para o treinamento do modelo v1 32k
|
||||
|
||||
### 2023-05-13
|
||||
- Limpar os códigos redundantes na versão antiga do tempo de execução no pacote de um clique: lib.infer_pack e uvr5_pack
|
||||
- Correção do bug de pseudo multiprocessamento no pré-processamento do conjunto de treinamento
|
||||
- Adição do ajuste do raio de filtragem mediana para o algoritmo de reconhecimento de inclinação da extração
|
||||
- Suporte à reamostragem de pós-processamento para exportação de áudio
|
||||
- A configuração "n_cpu" de multiprocessamento para treinamento foi alterada de "extração de f0" para "pré-processamento de dados e extração de f0"
|
||||
- Detectar automaticamente os caminhos de Index na pasta de registros e fornecer uma função de lista suspensa
|
||||
- Adicionar "Perguntas e respostas frequentes" na página da guia (você também pode consultar o wiki do RVC no github)
|
||||
- Durante a inferência, o pitch da colheita é armazenado em cache quando se usa o mesmo caminho de áudio de entrada (finalidade: usando a extração do pitch da colheita, todo o pipeline passará por um processo longo e repetitivo de extração do pitch. Se o armazenamento em cache não for usado, os usuários que experimentarem diferentes configurações de raio de filtragem de timbre, Index e mediana de pitch terão um processo de espera muito doloroso após a primeira inferência)
|
||||
|
||||
### 2023-05-14
|
||||
- Use o envelope de volume da entrada para misturar ou substituir o envelope de volume da saída (pode aliviar o problema de "muting de entrada e ruído de pequena amplitude de saída"). Se o ruído de fundo do áudio de entrada for alto, não é recomendável ativá-lo, e ele não é ativado por padrão (1 pode ser considerado como não ativado)
|
||||
- Suporte ao salvamento de modelos pequenos extraídos em uma frequência especificada (se você quiser ver o desempenho em épocas diferentes, mas não quiser salvar todos os pontos de verificação grandes e extrair manualmente modelos pequenos pelo processamento ckpt todas as vezes, esse recurso será muito prático)
|
||||
- Resolver o problema de "erros de conexão" causados pelo proxy global do servidor, definindo variáveis de ambiente
|
||||
- Oferece suporte a modelos v2 pré-treinados (atualmente, apenas as versões 40k estão disponíveis publicamente para teste e as outras duas taxas de amostragem ainda não foram totalmente treinadas)
|
||||
- Limita o volume excessivo que excede 1 antes da inferência
|
||||
- Ajustou ligeiramente as configurações do pré-processamento do conjunto de treinamento
|
||||
|
||||
|
||||
#######################
|
||||
|
||||
Histórico de registros de alterações:
|
||||
|
||||
### 2023-04-09
|
||||
- Parâmetros de treinamento corrigidos para melhorar a taxa de utilização da GPU: A100 aumentou de 25% para cerca de 90%, V100: 50% para cerca de 90%, 2060S: 60% para cerca de 85%, P40: 25% para cerca de 95%; melhorou significativamente a velocidade de treinamento
|
||||
- Parâmetro alterado: total batch_size agora é por GPU batch_size
|
||||
- Total_epoch alterado: limite máximo aumentado de 100 para 1000; padrão aumentado de 10 para 20
|
||||
- Corrigido o problema da extração de ckpt que reconhecia o pitch incorretamente, causando inferência anormal
|
||||
- Corrigido o problema do treinamento distribuído que salvava o ckpt para cada classificação
|
||||
- Aplicada a filtragem de recursos nan para extração de recursos
|
||||
- Corrigido o problema com a entrada/saída silenciosa que produzia consoantes aleatórias ou ruído (os modelos antigos precisavam ser treinados novamente com um novo conjunto de dados)
|
||||
|
||||
### Atualização 2023-04-16
|
||||
- Adicionada uma mini-GUI de alteração de voz local em tempo real, iniciada com um clique duplo em go-realtime-gui.bat
|
||||
- Filtragem aplicada para bandas de frequência abaixo de 50 Hz durante o treinamento e a inferência
|
||||
- Diminuição da extração mínima de tom do pyworld do padrão 80 para 50 para treinamento e inferência, permitindo que vozes masculinas de tom baixo entre 50-80 Hz não sejam silenciadas
|
||||
- A WebUI suporta a alteração de idiomas de acordo com a localidade do sistema (atualmente suporta en_US, ja_JP, zh_CN, zh_HK, zh_SG, zh_TW; o padrão é en_US se não for suportado)
|
||||
- Correção do reconhecimento de algumas GPUs (por exemplo, falha no reconhecimento da V100-16G, falha no reconhecimento da P4)
|
||||
|
||||
### Atualização de 2023-04-28
|
||||
- Atualizadas as configurações do Index faiss para maior velocidade e qualidade
|
||||
- Removida a dependência do total_npy; o futuro compartilhamento de modelos não exigirá a entrada do total_npy
|
||||
- Restrições desbloqueadas para as GPUs da série 16, fornecendo configurações de inferência de 4 GB para GPUs com VRAM de 4 GB
|
||||
- Corrigido o erro na separação do acompanhamento vocal do UVR5 para determinados formatos de áudio
|
||||
- A mini-GUI de alteração de voz em tempo real agora suporta modelos de pitch não 40k e que não são lentos
|
||||
|
||||
### Planos futuros:
|
||||
Recursos:
|
||||
- Opção de adição: extrair modelos pequenos para cada epoch salvo
|
||||
- Adicionar opção: exportar mp3 adicional para o caminho especificado durante a inferência
|
||||
- Suporte à guia de treinamento para várias pessoas (até 4 pessoas)
|
||||
|
||||
Modelo básico:
|
||||
- Coletar arquivos wav de respiração para adicionar ao conjunto de dados de treinamento para corrigir o problema de sons de respiração distorcidos
|
||||
- No momento, estamos treinando um modelo básico com um conjunto de dados de canto estendido, que será lançado no futuro
|
||||
@@ -16,7 +16,7 @@ Uma estrutura de conversão de voz fácil de usar baseada em VITS.
|
||||
</div>
|
||||
|
||||
------
|
||||
[**Changelog**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_EN.md) | [**FAQ (Frequently Asked Questions)**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/FAQ-(Frequently-Asked-Questions))
|
||||
[**FAQ (Frequently Asked Questions)**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/FAQ-(Frequently-Asked-Questions))
|
||||
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
|
||||
|
||||
|
||||
@@ -1,97 +0,0 @@
|
||||
|
||||
### 2023-08-13
|
||||
1- Düzenli hata düzeltmeleri
|
||||
- Minimum toplam epoch sayısını 1 olarak değiştirin ve minimum toplam epoch sayısını 2 olarak değiştirin
|
||||
- Ön eğitim modellerini kullanmama nedeniyle oluşan eğitim hatalarını düzeltin
|
||||
- Eşlik eden vokallerin ayrılmasından sonra grafik belleğini temizleyin
|
||||
- Faiss kaydetme yolu mutlak yoldan göreli yola değiştirilmiştir
|
||||
- Boşluk içeren yolu destekleyin (hem eğitim kümesi yolu hem de deney adı desteklenir ve artık hata rapor edilmez)
|
||||
- Filelist, zorunlu utf8 kodlamasını iptal eder
|
||||
- Gerçek zamanlı ses değişikliği sırasında faiss aramasından kaynaklanan CPU tüketim sorununu çözün
|
||||
|
||||
2- Temel güncellemeler
|
||||
- Geçerli en güçlü açık kaynak vokal ton çıkarma modeli RMVPE'yi eğitin ve RVC eğitimi, çevrimdışı/gerçek zamanlı çıkarım için kullanın, PyTorch/Onnx/DirectML destekler
|
||||
- Pytorch_DML aracılığıyla AMD ve Intel grafik kartları için destek ekleyin
|
||||
|
||||
(1) Gerçek zamanlı ses değişimi (2) Çıkarım (3) Vokal eşlik ayrımı (4) Şu anda desteklenmeyen eğitim, CPU eğitimine geçiş yapacaktır; Onnx_Dml ile gpu için RMVPE çıkarımını destekler
|
||||
|
||||
|
||||
### 2023-06-18
|
||||
- Yeni ön eğitilmiş v2 modeller: 32k ve 48k
|
||||
- F0 modeli çıkarım hatalarını düzeltme
|
||||
- Eğitim kümesi 1 saati aşarsa, özelliği şekil açısından küçültmek için otomatik minibatch-kmeans yapın, böylece indeks eğitimi, eklemesi ve araması çok daha hızlı olur.
|
||||
- Bir oyunca vokal2guitar huggingface alanı sağlama
|
||||
- Aykırı kısa kesim eğitim kümesi seslerini otomatik olarak silme
|
||||
- Onnx dışa aktarma sekmesi
|
||||
|
||||
Başarısız deneyler:
|
||||
- ~~Özellik çıkarımı: zamansal özellik çıkarımı ekleme: etkili değil~~
|
||||
- ~~Özellik çıkarımı: PCAR boyut azaltma ekleme: arama daha yavaş~~
|
||||
- ~~Eğitim sırasında rastgele veri artırma: etkili değil~~
|
||||
|
||||
Yapılacaklar listesi:
|
||||
- ~~Vocos-RVC (küçük vokoder): etkili değil~~
|
||||
- ~~Eğitim için Crepe desteği: RMVPE ile değiştirildi~~
|
||||
- ~~Yarı hassas Crepe çıkarımı: RMVPE ile değiştirildi. Ve zor gerçekleştirilebilir.~~
|
||||
- F0 düzenleyici desteği
|
||||
|
||||
### 2023-05-28
|
||||
- v2 jupyter notebook, korece değişiklik günlüğü, bazı çevre gereksinimlerini düzeltme
|
||||
- Sesli olmayan ünsüz ve nefes koruma modu ekleme
|
||||
- Crepe-full ton algılama desteği ekleme
|
||||
- UVR5 vokal ayrımı: yankı kaldırma modelleri ve yankı kaldırma modelleri destekleme
|
||||
- İndeks adında deney adı ve sürüm ekleme
|
||||
- Toplu ses dönüşüm işleme ve UVR5 vokal ayrımı sırasında çıkış seslerinin ihracat formatını kullanıcıların manuel olarak seçmelerine olanak tanıma
|
||||
- v1 32k model eğitimi artık desteklenmiyor
|
||||
|
||||
### 2023-05-13
|
||||
- Tek tıklamayla paketin eski sürümündeki çalışma zamanındaki gereksiz kodları temizleme: lib.infer_pack ve uvr5_pack
|
||||
- Eğitim seti ön işleme içindeki sahte çoklu işlem hatasını düzeltme
|
||||
- Harvest ton tanıma algoritması için ortanca filtre yarıçap ayarı ekleme
|
||||
- Çıkış sesi için örnek alma örneği için yeniden örnekleme desteği ekleme
|
||||
- Eğitim için "n_cpu" çoklu işlem ayarı, "f0 çıkarma" yerine "veri ön işleme ve f0 çıkarma" için değiştirildi
|
||||
- Günlükler klasörü altındaki indeks yollarını otomatik olarak tespit etme ve bir açılır liste işlevi sağlama
|
||||
- Sekme sayfasına "Sıkça Sorulan Sorular ve Cevaplar"ı ekleme (ayrıca github RVC wiki'ye de bakabilirsiniz)
|
||||
- Çıkarım sırasında aynı giriş sesi yolunu kullanırken harvest tonunu önbelleğe alma (amaç: harvest ton çıkarımı kullanırken, tüm işlem hattı uzun ve tekrarlayan bir ton çıkarım işlemi geçirecektir. Önbellekleme kullanılmazsa, farklı timbre, indeks ve ton ortanca filtreleme yarıçapı ayarlarıyla deney yapan kullanıcılar, ilk çıkarım sonrası çok acı verici bir bekleme süreci yaşayacaktır)
|
||||
|
||||
### 2023-05-14
|
||||
- Girişin hacim zarfını çıktının hacim zarfıyla karıştırmak veya değiştirmek için girişin hacim zarfını kullanma (problemi "giriş sessizleştirme ve çıktı küçük
|
||||
|
||||
amplitüdlü gürültü" sorununu hafifletebilir. Giriş sesi arka plan gürültüsü yüksekse, açık olması önerilmez ve varsayılan olarak açık değildir (1 varsayılan olarak kapalı olarak kabul edilir)
|
||||
- Belirli bir frekansta filtreleme uygulama eğitim ve çıkarım için 50Hz'nin altındaki frekans bantları için
|
||||
- Pyworld'un varsayılan 80'den 50'ye minimum ton çıkarma sınırlamasını eğitim ve çıkarım için düşürme, 50-80Hz arasındaki erkek alçak seslerin sessizleştirilmemesine izin verme
|
||||
- WebUI, sistem yereli diline göre dil değiştirme (şu anda en_US, ja_JP, zh_CN, zh_HK, zh_SG, zh_TW'yi destekliyor; desteklenmeyen durumda varsayılan olarak en_US'ye geçer)
|
||||
- Belirli bir giriş sesi yolunu kullanırken harvest tonunu önbelleğe alma (amaç: harvest ton çıkarma kullanırken, tüm işlem hattı uzun ve tekrarlayan bir ton çıkarma süreci geçirecektir. Önbellekleme kullanılmazsa, farklı timbre, indeks ve ton ortanca filtreleme yarıçapı ayarlarıyla deney yapan kullanıcılar, ilk çıkarım sonrası çok acı verici bir bekleme süreci yaşayacaktır)
|
||||
|
||||
### 2023-04-09 Güncellemesi
|
||||
- GPU kullanım oranını artırmak için eğitim parametrelerini düzeltme: A100, %25'ten yaklaşık %90'a, V100: %50'den yaklaşık %90'a, 2060S: %60'tan yaklaşık %85'e, P40: %25'ten yaklaşık %95'e; eğitim hızını önemli ölçüde artırma
|
||||
- Parametre değişti: toplam_batch_size artık GPU başına batch_size
|
||||
- Toplam_epoch değişti: maksimum sınırı 1000'e yükseltildi; varsayılan 10'dan 20'ye yükseltildi
|
||||
- ckpt çıkarımı ile çalma tanıma hatasını düzeltme, anormal çıkarım oluşturan
|
||||
- Dağıtılmış eğitimde her sıra için ckpt kaydetme sorununu düzeltme
|
||||
- Özellik çıkarımı için NaN özellik filtrelemesi uygulama
|
||||
- Sessiz giriş/çıkışın rastgele ünsüzler veya gürültü üretme sorununu düzeltme (eski modeller yeni bir veri kümesiyle tekrar eğitilmelidir)
|
||||
|
||||
### 2023-04-16 Güncellemesi
|
||||
- Yerel gerçek zamanlı ses değiştirme mini-GUI'si ekleme, çift tıklayarak go-realtime-gui.bat ile başlayın
|
||||
- Eğitim ve çıkarım sırasında 50Hz'nin altındaki frekans bantlarını filtreleme uygulama
|
||||
- Pyworld'deki varsayılan 80'den 50'ye minimum ton çıkarma sınırlamasını eğitim ve çıkarım için düşürme, 50-80Hz arasındaki erkek alçak seslerin sessizleştirilmemesine izin verme
|
||||
- WebUI, sistem yereli diline göre dil değiştirme (şu anda en_US, ja_JP, zh_CN, zh_HK, zh_SG, zh_TW'yi destekliyor; desteklenmeyen durumda varsayılan olarak en_US'ye geçer)
|
||||
- Bazı GPU'ların tanınmasını düzeltme (örneğin, V100-16G tanınmama sorunu, P4 tanınmama sorunu)
|
||||
|
||||
### 2023-04-28 Güncellemesi
|
||||
- Daha hızlı hız ve daha yüksek kalite için faiss indeks ayarlarını yükseltme
|
||||
- Toplam_npy bağımlılığını kaldırma; gelecekteki model paylaşımları için total_npy girdisi gerekmeyecek
|
||||
- 16-serisi GPU'lar için kısıtlamaları açma, 4GB VRAM GPU'lar için 4GB çıkarım ayarları sağlama
|
||||
- Belirli ses biçimlerine yönelik UVR5 vokal eşlik ayrımındaki hata düzeltme
|
||||
- Gerçek zamanlı ses değiştirme mini-GUI şimdi 40k dışı ve tembel ton modellerini destekler
|
||||
|
||||
### Gelecekteki Planlar:
|
||||
Özellikler:
|
||||
- Her epoch kaydetmek için küçük modeller çıkar seçeneğini ekleme
|
||||
- Çıkarım sırasında çıkış seslerini belirtilen yolda ekstra mp3 olarak kaydetme seçeneğini ekleme
|
||||
- Birden fazla kişinin eğitim sekmesini destekleme (en fazla 4 kişiye kadar)
|
||||
|
||||
Temel model:
|
||||
- Bozuk nefes seslerinin sorununu düzeltmek için nefes alma wav dosyalarını eğitim veri kümesine eklemek
|
||||
- Şu anda genişletilmiş bir şarkı veri kümesiyle temel model eğitimi yapıyoruz ve gelecekte yayınlanacak
|
||||
@@ -17,7 +17,7 @@ VITS'e dayalı kullanımı kolay bir Ses Dönüşümü çerçevesi.
|
||||
</div>
|
||||
|
||||
------
|
||||
[**Değişiklik Geçmişi**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_TR.md) | [**SSS (Sıkça Sorulan Sorular)**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/SSS-(Sıkça-Sorulan-Sorular))
|
||||
[**SSS (Sıkça Sorulan Sorular)**](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI/wiki/SSS-(Sıkça-Sorulan-Sorular))
|
||||
|
||||
[**İngilizce**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
|
||||
|
||||
|
||||
Reference in New Issue
Block a user